
Introduction
System downtime costs large enterprises approximately $4,537 per minute, according to PagerDuty's 2024 analysis. Beyond direct revenue loss, incident response teams juggle fragmented tools—Slack for communication, PagerDuty for alerts, Jira for tracking—inflating Mean Time to Resolution (MTTR) by an estimated 15 minutes per incident.
FireHydrant is a modern incident management platform designed for DevOps and SRE teams consolidating fragmented workflows.
Built with web-first architecture and deep Slack integration, the platform eliminates manual coordination tasks and automates administrative burden that prevents engineers from focusing on resolution work.
TLDR:
- Consolidates alerting, on-call management, and incident response in one platform
- Automated dependency mapping and intelligent alert routing via Service Catalog
- AI Copilot automates retrospectives, summaries, and transcriptions
- Chat-native workflows reduce context switching during incidents
- Pricing starts at $9,600/year for Platform Pro (up to 20 responders)
What is FireHydrant Incident Management?
FireHydrant is an end-to-end incident management platform built specifically for DevOps teams, Site Reliability Engineers, and engineering organizations operating under "you build it, you run it" philosophies.
Unlike general-purpose ITSM tools designed for traditional IT service desks, FireHydrant focuses exclusively on software reliability workflows.
Architectural Approach
The platform uses a web-first, API-first architecture that provides deep programmatic access and infrastructure-as-code configuration through Terraform. This approach differs from purely chat-native tools by maintaining a robust web interface for configuration and analytics while enabling bi-directional Slack and Microsoft Teams integration that allows responders to declare, manage, and resolve incidents entirely within their chat interface.
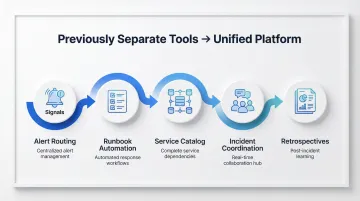
FireHydrant consolidates previously separate tools into a single platform:
- Alert routing and on-call scheduling (via its "Signals" product)
- Runbook automation and workflow orchestration
- Service cataloging with dependency mapping
- Incident coordination and timeline capture
- Post-incident retrospectives and analytics
Target Users and Use Cases
The platform serves mid-market to enterprise organizations managing complex microservices architectures. Primary users include:
- DevOps engineers coordinating cross-functional incident response
- SREs tracking reliability metrics and improvement patterns
- Engineering leaders analyzing incident trends and team performance
- On-call responders requiring mobile access during after-hours incidents
Within the broader incident management ecosystem, FireHydrant works alongside monitoring tools (Datadog, New Relic) and alerting platforms (PagerDuty, Opsgenie) rather than replacing them.
The platform ingests alerts from these systems and provides the coordination layer that transforms individual alerts into structured incident response workflows aligned with SRE and DevOps practices.
Specialized Requirements Consideration
FireHydrant excels for software incident management, but organizations with specific compliance requirements should carefully evaluate platform alignment with their regulatory frameworks.
Emergency management agencies, government organizations, and public sector entities often require adherence to FEMA NIMS (National Incident Management System) and ICS (Incident Command System) standards.
For these specialized contexts, platforms like BCG's DisasterLAN offer FEMA NIMS STEP certification—designed specifically for emergency response coordination rather than software incidents.
Core Features and Capabilities
Alerting and On-Call Management
FireHydrant's Signals product handles alert ingestion from monitoring tools including Datadog, New Relic, Honeycomb, BugSnag, and Prometheus Alertmanager. The platform routes alerts to specific teams based on service ownership. When predefined thresholds are met, it automatically escalates alerts to full incidents.
Alert routing operates through:
- Maps alerts to owning teams automatically based on service definitions
- Conditional escalation rules that convert critical alerts to full incidents
- Integration with existing on-call platforms (PagerDuty, Opsgenie, Splunk On-Call)
- Manual incident declaration via web UI or Slack commands like
/fh new
Automated Runbooks
FireHydrant replaces static wiki playbooks with executable Runbooks that trigger automatically based on incident conditions such as severity, affected service, or incident type.
Runbook automation capabilities include:
| Feature | Capability |
|---|---|
| Conditional Logic | Execute steps based on incident severity, type, or infrastructure |
| Automated Actions | Create Slack channels, video bridges, Jira tickets, status page updates |
| Role Assignment | Automatically assign Incident Commander to on-call schedules |
| Notification Workflows | Alert stakeholders through multiple channels simultaneously |
Qlik reported that FireHydrant's automation saved 5-10 minutes per incident by eliminating manual channel creation and role assignment tasks.
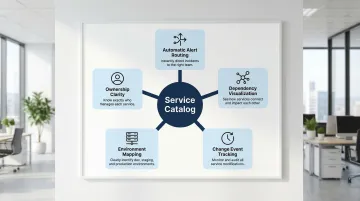
Service Catalog Integration
The Service Catalog serves as a central repository, mapping services to owners, dependencies, and recent changes. Organizations ingest service definitions from Kubernetes, GitHub, Terraform, and existing catalogs like Backstage.
Key service catalog benefits:
- Automatic alert routing to correct teams based on service ownership
- Dependency visualization showing potential impact scope during incidents
- Change event tracking that correlates deployments with incident timing
- Environment mapping that distinguishes production vs. staging incidents
- Eliminates the "who owns this?" question that typically delays initial response
AI and Automation Features
Building on these foundational capabilities, FireHydrant's AI Copilot reduces administrative toil through three primary capabilities:
Incident Summaries: Generates real-time summaries of Slack channel activity to bring late-joining responders up to speed instantly without reading hundreds of messages.
Meeting Transcription: Transcribes Zoom and Google Meet incident bridge calls, extracting key decisions and action items directly into the incident timeline.
Retrospective Drafting: Analyzes chat logs, timeline events, and meeting transcripts to automatically draft retrospectives, suggesting contributing factors and remediation actions based on incident data.
These features address the documentation burden that often causes retrospective delays—Snyk achieved 100% adoption within one week driven by reduced manual documentation requirements.
Collaboration and Communication Tools
FireHydrant maintains deep integration with communication platforms beyond simple notifications:
Slack Integration:
- Automatic incident channel creation with standardized naming
- In-channel commands for status updates and role assignments
- Timeline capture of all channel messages and reactions
- Stakeholder notification without requiring Slack access
Microsoft Teams Integration:
- Similar bi-directional functionality for Teams-centric organizations
- Channel creation and management through Teams interface
- Message threading and timeline synchronization
Role management features include:
- Predefined roles (Incident Commander, Scribe, Subject Matter Expert)
- Clear chain of command visible to all participants
- Automatic handoff documentation when roles change
Analytics and Reporting
FireHydrant tracks incident metrics to support reliability improvement programs:
- MTTR (Mean Time to Resolution): Average time from incident start to resolution
- MTTD (Mean Time to Detection): Average time from incident occurrence to detection
- Incident Frequency: Count and trends over time by severity and service
- Severity Patterns: Distribution of incidents across severity levels
- Service Reliability: Incident concentration by service or team
Analytics dashboards enable engineering leaders to identify systemic issues, track improvement initiatives, and justify reliability investments with quantifiable data.
How FireHydrant Manages the Incident Lifecycle
Incident Detection and Declaration
Incidents enter FireHydrant through multiple channels:
Automated Detection:
- Webhook ingestion from monitoring tools triggers automatic incident creation
- Alert routing rules determine which alerts escalate to full incidents
- Service catalog context enriches incidents with ownership and dependency data
Manual Declaration:
- Web UI incident creation form with severity and service selection
- Slack command
/fh newinitiates incidents directly from chat - Mobile app declaration for on-call responders
Upon declaration, FireHydrant immediately executes the appropriate runbook:
- Creates dedicated Slack incident channel
- Assembles response team based on service ownership
- Assigns roles according to on-call schedules
- Generates video bridge link
- Creates associated Jira ticket
- Posts initial status page update

This automated setup reduces the coordination overhead that typically consumes the first 10-15 minutes of incident response.
Response and Resolution
During active incidents, FireHydrant coordinates response through several mechanisms:
- Timeline Capture: Automatically logs all activities—Slack messages, status changes, role assignments, runbook completions—into a unified timeline
- Role-Based Coordination: Clear role assignments (Commander, Scribe, SME) ensure accountability while SMEs focus on technical investigation
- Stakeholder Communication: Status updates synchronize across Slack, Jira, and public status pages automatically
- Resource Integration: Responders access runbooks, deployments, service dependencies, and historical incidents without leaving the incident channel
This eliminates the traditional "scribe" role and reduces context switching during high-pressure situations.
Post-Incident Analysis
Once incidents resolve, the platform addresses the retrospective bottleneck through automation:
- Pre-populates retrospectives with timeline data, participant lists, affected services, and duration metrics
- Provides standardized templates ensuring consistent analysis across incidents
- Uses AI Copilot to suggest retrospective content based on incident data
This eliminates the "blank page" problem and reduces the time from incident resolution to published retrospective from days to hours. Organizations following NIMS/ICS principles (like those using BCG's DLAN system) similarly benefit from template-guided documentation aligned with FEMA guidelines.
Continuous Improvement
The platform transforms incident data into reliability improvements:
- Analytics reveal which services generate the most incidents and which teams experience the longest MTTR
- The platform integrates retrospective action items with Jira and Linear, ensuring follow-through on improvement commitments
- Teams refine runbooks based on what worked during actual incidents
This continuous feedback loop improves response effectiveness over time.

Use Cases and Target Organizations
FireHydrant serves organizations across multiple sectors:
Primary Use Cases:
- Software and SaaS Companies — Organizations with microservices architectures benefit from service catalog dependency mapping and incident correlation with deployment changes
- E-commerce Platforms — High-traffic retail sites coordinate rapid response during revenue-impacting incidents, particularly during peak shopping periods
- Financial Services — Fintech companies manage regulated incident response where documentation and audit trails are mandatory compliance requirements
Organization Size Considerations:
- Startups (10-50 engineers): Benefit from standardized processes as teams grow
- Mid-Market (50-500 engineers): Primary sweet spot for platform adoption
- Enterprise (500+ engineers): Require advanced features like SSO, audit logs, and RBAC available in Enterprise tier
Specialized Sector Considerations
While FireHydrant excels at software incident management, government and regulated industries often require compliance with specific emergency response frameworks.
Emergency management agencies, public safety organizations, and government entities typically need adherence to FEMA NIMS (National Incident Management System) and ICS (Incident Command System) standards for physical emergency response coordination. For these specialized contexts, platforms designed specifically for emergency operations—such as BCG's FEMA NIMS STEP-certified DisasterLAN—provide the framework alignment required for regulatory compliance.
Organizations should evaluate whether their compliance requirements require specialized emergency management solutions or whether software-focused platforms like FireHydrant meet their operational needs.
Evaluating FireHydrant: Key Considerations
Workflow and Architectural Fit
Chat-Native vs. Web-First: FireHydrant balances both approaches. Teams that live in Slack may prefer purely chat-native alternatives like incident.io.
Organizations requiring robust configuration interfaces and analytics dashboards benefit from FireHydrant's web-first foundation.
Integration Requirements: Assess whether FireHydrant integrates natively with your specific toolchain. The platform offers extensive integrations including Datadog, New Relic, Jira, ServiceNow, GitHub, and Kubernetes, but organizations with custom or niche monitoring tools should verify compatibility.
Automation Depth: Teams seeking to eliminate manual coordination tasks should prioritize platforms with executable runbooks that perform actions (create channels, page users, update tickets) rather than simple checklists.
Customization and Flexibility
Service Catalog Import: Determine whether the platform can import existing service definitions from your current systems (Backstage, PagerDuty service directories, Terraform configurations).
Runbook Customization: Consider how easily teams can modify runbooks to match organizational workflows without requiring vendor support.
Post-Incident Review Templates: Organizations with established post-mortem processes need platforms that support custom templates aligned with company standards.
Total Cost of Ownership
Unified platforms like FireHydrant can reduce TCO by consolidating separate contracts for alerting, status pages, and incident coordination.
Calculate potential savings from eliminating redundant tools against the platform's licensing costs.
Hidden costs to consider:
- Status page inclusion (included or charged separately?)
- On-call scheduling fees (additional charges or bundled?)
- AI feature access (base pricing or enterprise-tier only?)
Implementation and Support
Deployment Timeline: Smaller teams typically achieve operational status within 2-4 weeks, while enterprise rollouts may require 6-8 weeks for complete integration and training.
Vendor Responsiveness: Assess support models, response time commitments, and whether the vendor provides dedicated customer success resources during implementation.
Compliance and Specialized Requirements
Organizations in regulated sectors should verify that incident management platforms meet their specific compliance frameworks.
FireHydrant provides capabilities suitable for many compliance requirements:
- Audit logs for accountability tracking
- SSO for secure access control
- Documentation features for compliance reporting
Specialized sectors may require additional certifications beyond standard software incident management. Emergency management organizations, government agencies, and public safety entities coordinating physical emergency responses need NIMS/ICS compliance.
For these contexts, platforms like BCG's DLAN offer FEMA NIMS STEP certification specifically designed for emergency response operations aligned with federal emergency management standards.
Pricing and Implementation
Pricing Structure
FireHydrant offers transparent pricing compared to competitors with hidden add-ons:
Free Trial: 14-day trial of Platform Pro tier with full feature access
Platform Pro — $9,600 per year including:
- Up to 20 responders
- 5 runbooks
- Slack/Teams chatbots
- Unlimited public status pages
- Basic analytics and reporting
- Standard integrations
Enterprise — Custom pricing with additional features:
- Unlimited runbooks
- Private incidents
- AI Copilot capabilities
- Premium support with dedicated CSM
- Advanced security (SSO, audit logs, RBAC)
- Custom SLA commitments
Implementation Process
FireHydrant's implementation follows a four-week onboarding timeline:
- Integration Setup (Week 1): Connect chat platforms, monitoring tools, and ticketing systems through guided quickstart
- Service Catalog Population (Week 1-2): Import services from existing sources or manually define service ownership
- Runbook Configuration (Week 2-3): Create initial runbooks for common incident types
- Team Training (Week 3-4): Conduct incident simulation exercises to familiarize responders
- Production Rollout (Week 4): Enable automatic incident creation from production alerts
Total Cost of Ownership
When budgeting for incident management software, account for these implementation factors beyond licensing:
- Staff time for implementation: Typically 40-60 hours for mid-market organizations
- Ongoing maintenance: Minimal due to SaaS model, primarily runbook updates
- Training costs: Initial training plus onboarding for new team members
- Consolidation savings: Potential elimination of separate alerting, status page, or documentation tools
Frequently Asked Questions
What is FireHydrant incident management software?
FireHydrant is an end-to-end platform for managing software incidents from detection through resolution. It consolidates alerting, on-call scheduling, runbook automation, and retrospectives into a unified system for DevOps and SRE teams.
How do you measure the effectiveness of an incident management process?
Key effectiveness metrics include MTTR (Mean Time to Resolution), MTTA (Mean Time to Acknowledge), incident frequency trends, severity distribution, and team satisfaction scores. FireHydrant tracks these metrics automatically to measure reliability initiative impact.
What is incident management in software?
Software incident management is the process of identifying, responding to, and resolving service disruptions to minimize user impact and restore normal operations. It includes detection, coordination, resolution, documentation, and retrospective analysis.
What are the key features of FireHydrant?
Core capabilities include automated runbooks with conditional logic, service catalog with dependency mapping, AI-assisted retrospectives, Slack/Teams integration, analytics and reporting, and third-party integrations with monitoring and ticketing tools.
How does FireHydrant compare to other incident management tools?
FireHydrant differentiates through its Service Catalog-centric approach that drives intelligent automation, web-first architecture with strong chat integration, and template-driven retrospectives. The platform balances automation depth with ease of use.
Is FireHydrant suitable for enterprise organizations?
Yes, FireHydrant's Enterprise tier provides SSO, audit logs, RBAC, and premium support suitable for large organizations. However, requirements vary by industry—software companies typically find strong alignment, while specialized sectors like emergency management may need platforms with specific compliance certifications. For example, public sector emergency response operations require FEMA NIMS STEP compliance, which Buffalo Computer Graphics' DLAN system provides as the first and only fully compliant incident management platform.


